7 Simple and Overlooked Technical SEO Tweaks for Your Blog
Google and MDN docs reveal proper ways to structure a blog, yet most blogs overlook these simple technical SEO tweaks.

I've been creating many blog templates for the Webstudio Marketplace, incorporating numerous lesser-known technical SEO tactics. I'd like to share these tactics with you.
While "well-known" and "lesser-known" are relative, I rarely see these technical SEO tactics on most blogs, and they are straightforward to implement.
Note: This post won't cover the typical SEO tactics like adding internal links using your target keywords, site structure, using semantically related keywords, handling duplicate content, and the many other things you'll find in most blog posts. This will cover what I rarely or never see discussed in other technical SEO blogs.
Semantic tags
Most sites use semantic tags. However, there are several places where they are rarely implemented.
Semantic tags provide search engines, screen readers, and even you, the website builder, with better clarity of your web pages' various areas. Visually, people can easily distinguish where the start of an article is, for example, but search engines have to make an educated guess. The article tag, for example, essentially tells search engines, "The article is contained here."
Blog listing page
The page listing all of your blog posts should use the article tag for every post.
If you have 50 posts, then there should be 50 article tags.
Here's the official definition of the article tag:
The HTML element represents a self-contained composition in a document, page, application, or site, which is intended to be independently distributable or reusable (e.g., in syndication). Examples include: a forum post, a magazine or newspaper article, or a blog entry, a product card, a user-submitted comment, an interactive widget or gadget, or any other independent item of content.
The MDN docs go on to spell it out more clearly:
A given document can have multiple articles in it; for example, on a blog that shows the text of each article one after another as the reader scrolls, each post would be contained in anelement, possibly with one or mores within.
If you're using Webstudio, head over to the component settings and change it like this:
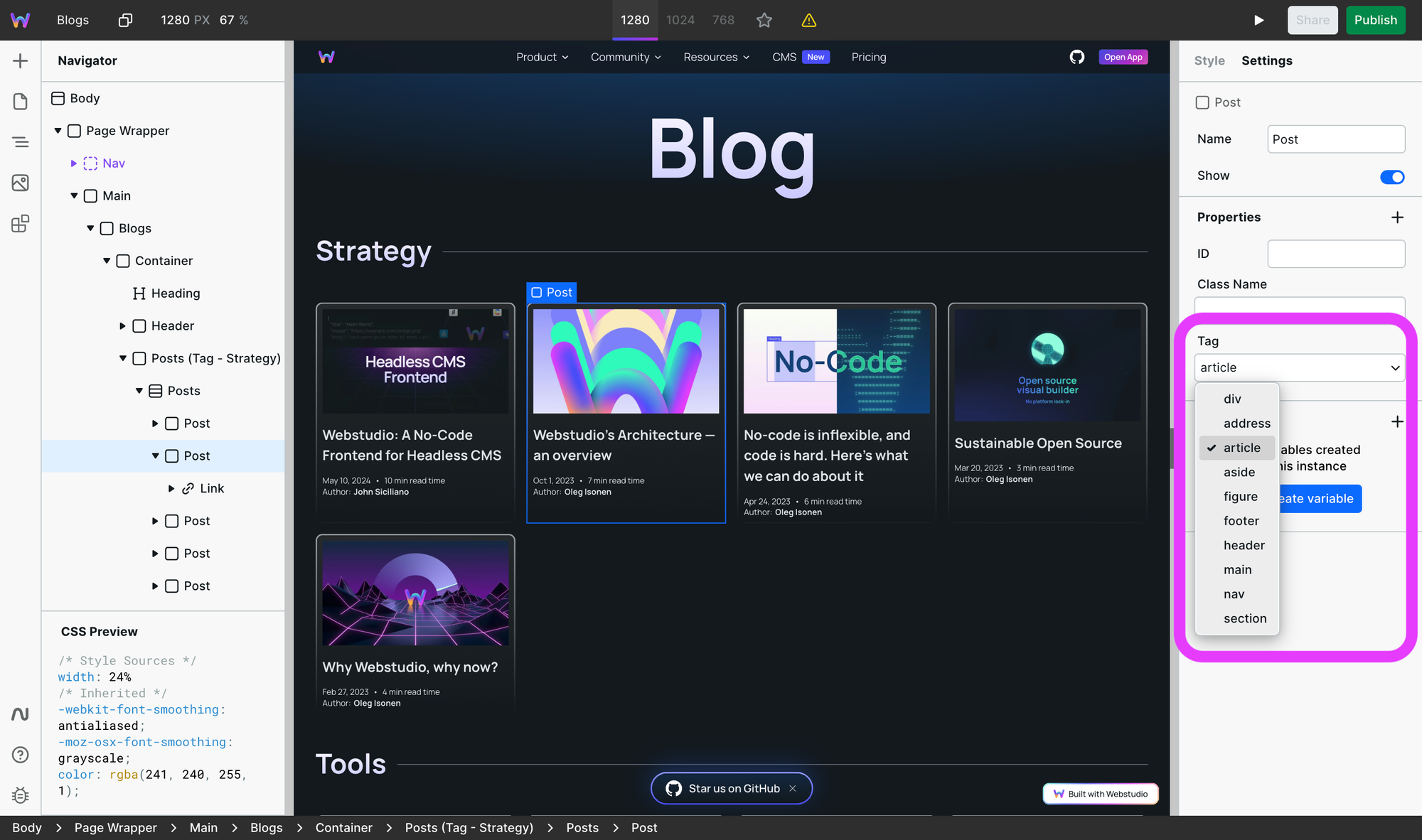
When search engines such as Google crawl the page, they'll better understand the relationship and purpose of all those links.
Blog post template
The post can and should be divided into several semantic tags, including a header and footer.
That's right, the header and footer are not only reserved for the start and end of the page.
Header tag
Your blog post intro should use the header tag and contain all the introductory content, including the H1, image, author, excerpt, and dates.
Here's the official definition of the header tag:
The HTML element represents introductory content, typically a group of introductory or navigational aids. It may contain some heading elements but also a logo, a search form, an author name, and other elements.
They go on to provide an example code snippet showing its use within an article:
<article>
<header>
<h2>The Planet Earth</h2>
<p>
Posted on Wednesday, <time datetime="2017-10-04">4 October 2017</time> by
Jane Smith
</p>
</header>
<p>
We live on a planet that's blue and green, with so many things still unseen.
</p>
<p><a href="https://example.com/the-planet-earth/">Continue reading…</a></p>
</article>
Footer tag
The same holds true for the "footer" of your post. Wrap the author and any related posts in the footer tag.
Here's the official definition of the footer tag:
The HTML element represents a footer for its nearest ancestor sectioning content or sectioning root element. Atypically contains information about the author of the section, copyright data or links to related documents.
If you're using Webstudio, here's what that looks like:

Author
Google uses "a mix of factors that can help determine which content demonstrates aspects of experience, expertise, authoritativeness, and trustworthiness, or what we call E-E-A-T."
Google goes on to talk about the importance of the person behind the content:
Something that helps people intuitively understand the E-E-A-T of content is when it's clear who created it. That's the "Who" to consider. When creating content, here are some who-related questions to ask yourself:Is it self-evident to your visitors who authored your content?Do pages carry a byline, where one might be expected?Do bylines lead to further information about the author or authors involved, giving background about them and the areas they write about?
If you're clearly indicating who created the content, you're likely aligned with the concepts of E-E-A-T and on a path to success. We strongly encourage adding accurate authorship information, such as bylines to content where readers might expect it.
The following are several technical SEO blog tactics you can use to help Google understand the author.
Display and link the author
First and foremost, display the author of the post and link to a dedicated page for that author.
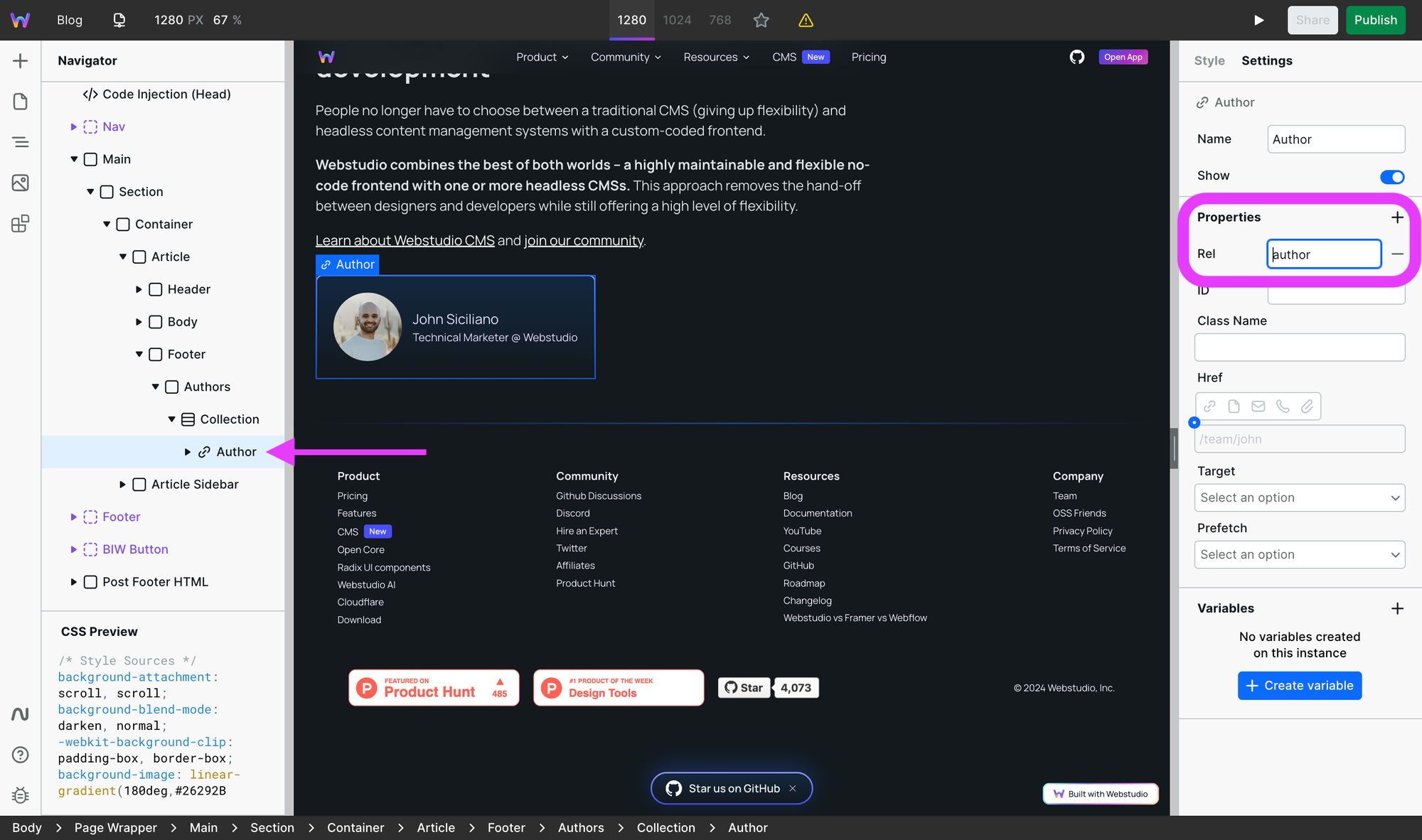
Rel on the author link
The link to the author page should have rel=author on it. Rel is short for relationship and helps search engines (and screen readers) understand the nature of the link.
From MDN:
This attribute states that the linked document represents the author of the current page.
Here's how to set that on Webstudio:
Schema on the author page
Including schema about the post is common, but not the author.
The author page should include profile page structured data as "Google Search makes use of this markup when disambiguating the creator," among other things, such as providing additional information to be displayed in the Google search results.
Plus, Google's article structured data documentation states, "If the URL is an internal profile page, we recommend marking up that author using profile page structured data."
If you are using Webstudio, use an HTML embed and bindings to dynamically change the info depending on which author is viewed (if there is only one author, you can make it static).
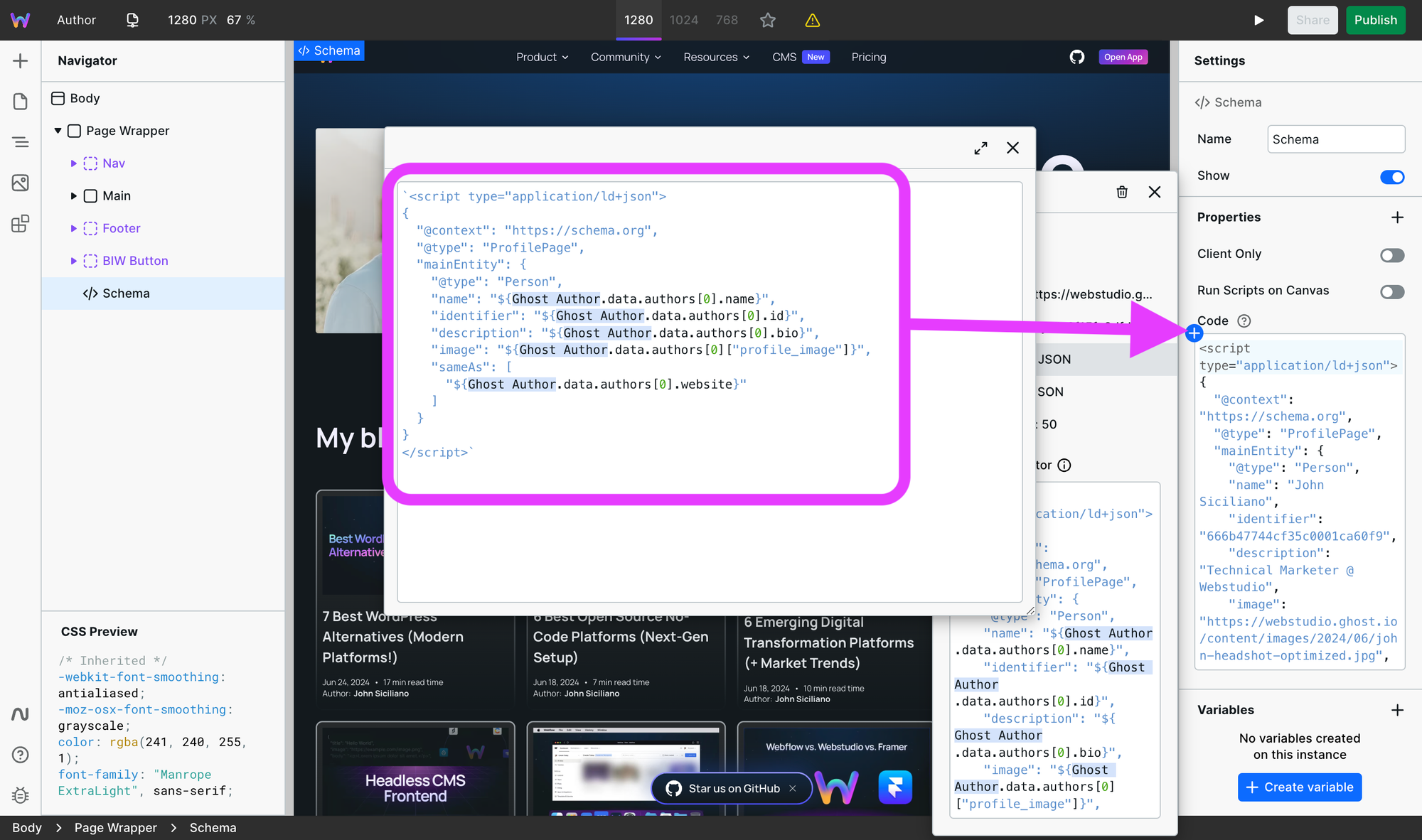
The schema used for this blog is as follows (note the variables are project-dependent, so be sure to use your own):
`<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "ProfilePage",
"mainEntity": {
"@type": "Person",
"name": "${Ghost.data.authors[0].name}",
"identifier": "${Ghost.data.authors[0].id}",
"description": "${Ghost.data.authors[0].bio}",
"image": "${Ghost.data.authors[0]["profile_image"]}",
"sameAs": [
"${Ghost.data.authors[0].website}"
]
}
}
</script>`
Some well-known technical SEO tactics for your blog
While this won't go into great depth, I'll highlight several easy things to implement that many blogs aren't doing.
Article schema
Article schema "can help Google understand more about the web page and show better title text, images, and date information for the article in search results on Google Search and other properties."
Be sure to include author information in the schema markup.
Here's what that looks like in Webstudio using dynamic bindings:
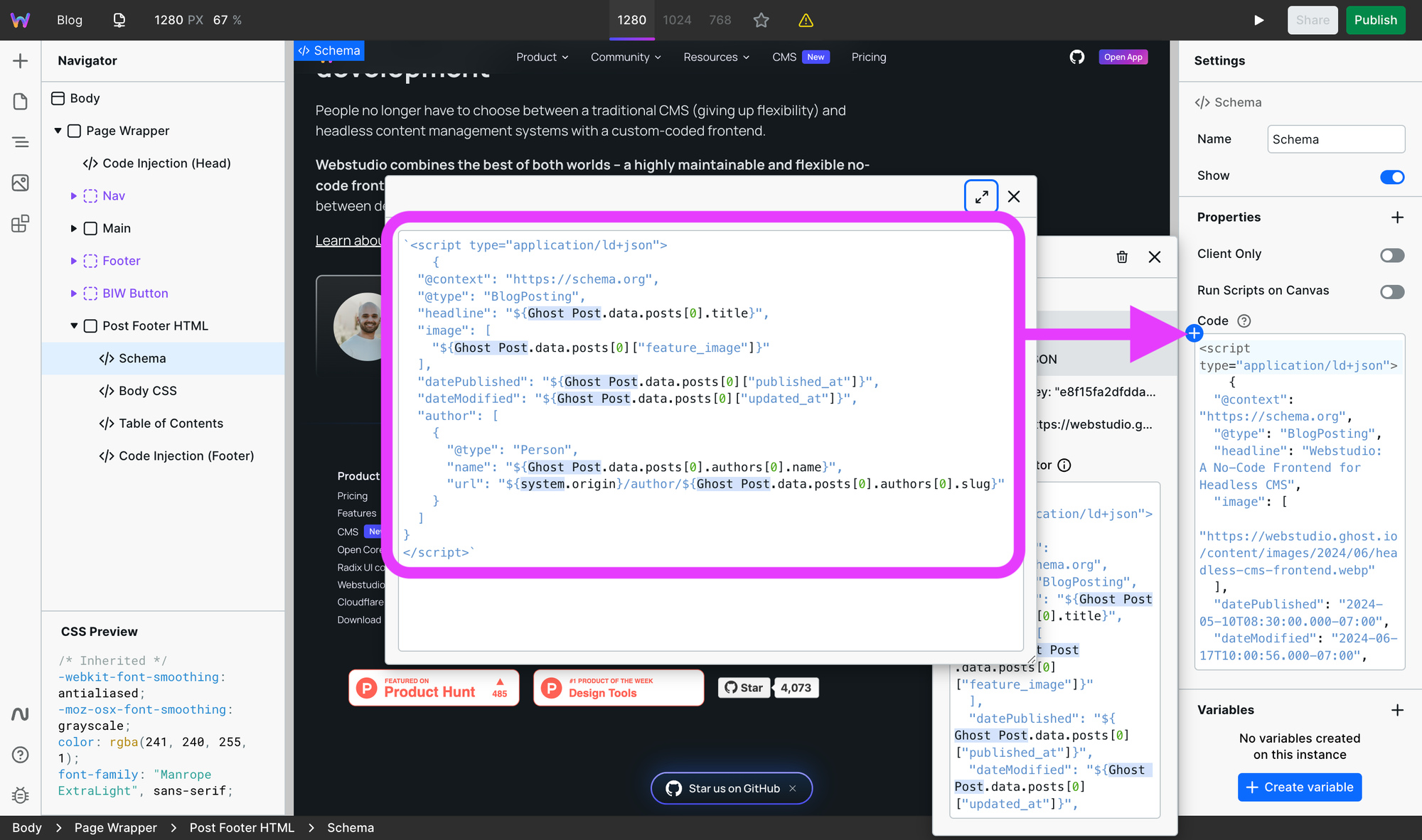
Eager load above the fold images
It may seem counterintuitive to load any image immediately as its counterpart, lazy loading, enables the image to load only when needed. However, eager loading above the fold images significantly improves the Largest Contentful Paint (LCP), a metric in the Core Web Vitals.
By eager loading the images above the fold, which is typically your blog post's featured/main image, the user sees the content they need the quickest, a signal Google looks at.
If you are having LCP issues, you'll see them in Google Search Console. You can also run audits using the online tool or locally in Chromium-based browsers.
In Webstudio, select the image and choose eager like this:
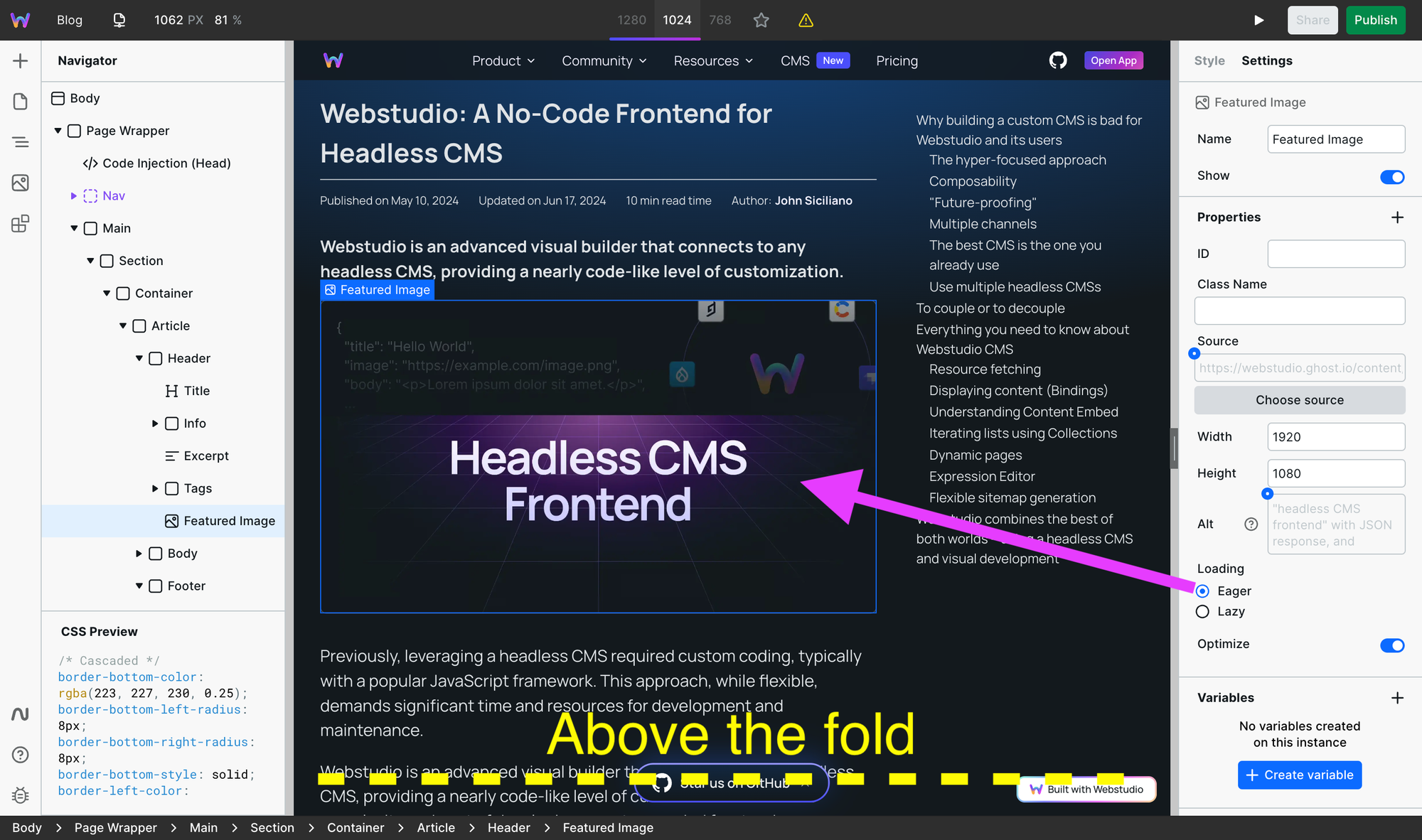
Use width and height attributes on images
Setting width and height attributes (not CSS styles) ensures visual stability when the page loads, reducing or eliminating any Layout Shift, another signal Google looks for.
Note: Webstudio automatically sets these values when inserting an image.
Without these dimensions, no space is reserved for the image, which loads slower than the surrounding text. The lack of reserved space causes the content below it to shift down once the image loads in. That's annoying for us users.
The following image depicts the space reserved even though the image hasn't loaded yet:
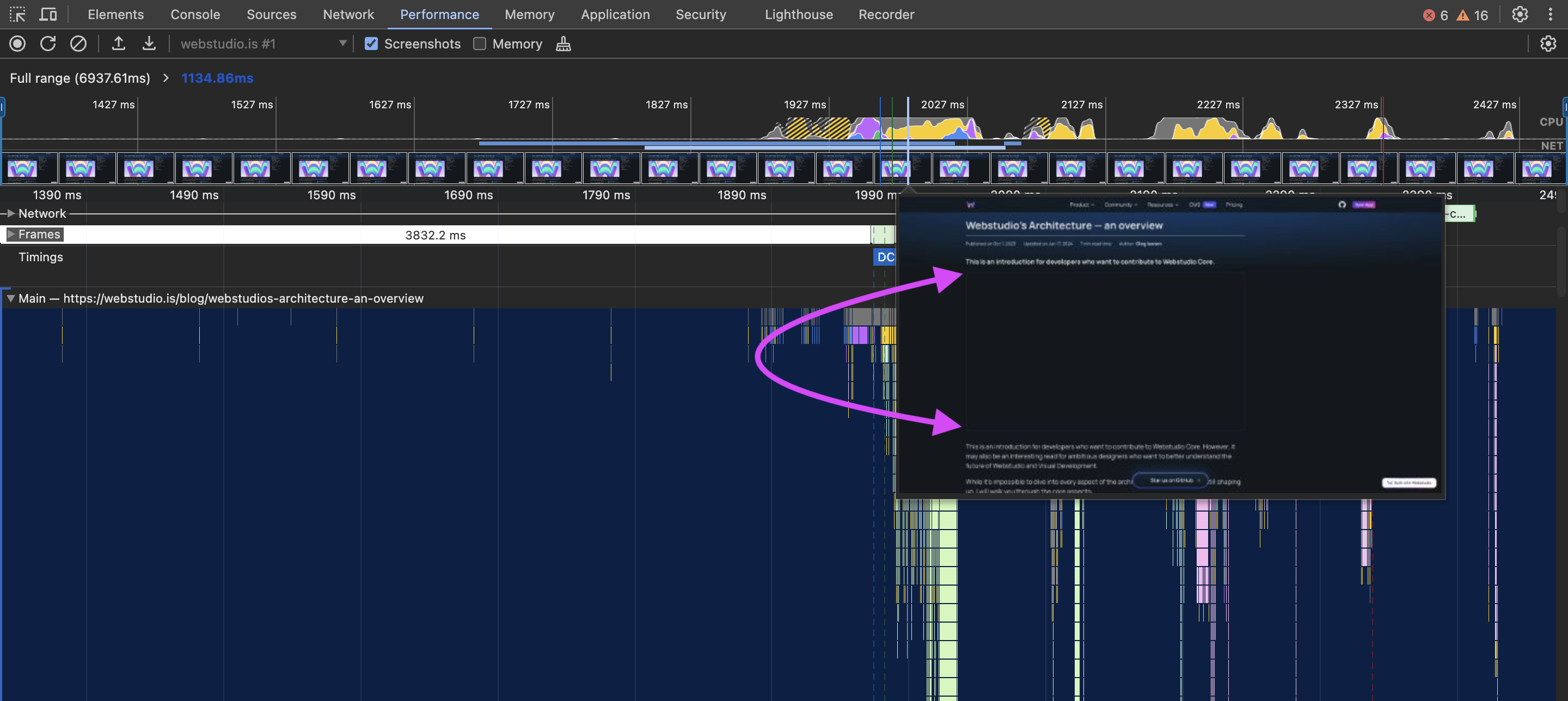
The dimensions ensure that the image's space is reserved once it loads. The dimensions don't need to be the exact size the image takes up; they are used to calculate the aspect ratio. The browser uses the calculated aspect ratio to reserve the proper space.
The image dimensions do matter if you use an image transformer, which will create a smaller version of the image instead of serving up the full-size asset.
Note: Images are automatically optimized in Webstudio.
Implementing these technical SEO tactics will help improve Google's ability to understand your content and who is behind it – a critical factor for enhancing search engine visibility.